 Medical devices are incredibly vulnerable to hacking attacks. In some cases it’s because of software defects that allow for exploits, like buffer overflows, SQL injection or insecure direct object references. In other cases, you can blame misconfigurations, lack of encryption (or weak encryption), non-secure data/control networks, unfettered wireless access, and worse.
Medical devices are incredibly vulnerable to hacking attacks. In some cases it’s because of software defects that allow for exploits, like buffer overflows, SQL injection or insecure direct object references. In other cases, you can blame misconfigurations, lack of encryption (or weak encryption), non-secure data/control networks, unfettered wireless access, and worse.
Why would hackers go after medical devices? Lots of reasons. To name but one: It’s a potential terrorist threat against real human beings. Remember that Dick Cheney famously disabled the wireless capabilities of his implanted heart monitor for fear of an assassination attack.
Certainly healthcare organizations are being targeted for everything from theft of medical records to ransomware. To quote the report “Hacking Healthcare IT in 2016,” from the Institute for Critical Infrastructure Technology (ICIT):
The Healthcare sector manages very sensitive and diverse data, which ranges from personal identifiable information (PII) to financial information. Data is increasingly stored digitally as electronic Protected Health Information (ePHI). Systems belonging to the Healthcare sector and the Federal Government have recently been targeted because they contain vast amounts of PII and financial data. Both sectors collect, store, and protect data concerning United States citizens and government employees. The government systems are considered more difficult to attack because the United States Government has been investing in cybersecurity for a (slightly) longer period. Healthcare systems attract more attackers because they contain a wider variety of information. An electronic health record (EHR) contains a patient’s personal identifiable information, their private health information, and their financial information.
EHR adoption has increased over the past few years under the Health Information Technology and Economics Clinical Health (HITECH) Act. Stan Wisseman [from Hewlett-Packard] comments, “EHRs enable greater access to patient records and facilitate sharing of information among providers, payers and patients themselves. However, with extensive access, more centralized data storage, and confidential information sent over networks, there is an increased risk of privacy breach through data leakage, theft, loss, or cyber-attack. A cautious approach to IT integration is warranted to ensure that patients’ sensitive information is protected.”
Let’s talk devices. Those could be everything from emergency-room monitors to pacemakers to insulin pumps to X-ray machines whose radiation settings might be changed or overridden by malware. The ICIT report says,
Mobile devices introduce new threat vectors to the organization. Employees and patients expand the attack surface by connecting smartphones, tablets, and computers to the network. Healthcare organizations can address the pervasiveness of mobile devices through an Acceptable Use policy and a Bring-Your-Own-Device policy. Acceptable Use policies govern what data can be accessed on what devices. BYOD policies benefit healthcare organizations by decreasing the cost of infrastructure and by increasing employee productivity. Mobile devices can be corrupted, lost, or stolen. The BYOD policy should address how the information security team will mitigate the risk of compromised devices. One solution is to install software to remotely wipe devices upon command or if they do not reconnect to the network after a fixed period. Another solution is to have mobile devices connect from a secured virtual private network to a virtual environment. The virtual machine should have data loss prevention software that restricts whether data can be accessed or transferred out of the environment.
The Internet of Things – and the increased prevalence of medical devices connected hospital or home networks – increase the risk. What can you do about it? The ICIT report says,
The best mitigation strategy to ensure trust in a network connected to the internet of things, and to mitigate future cyber events in general, begins with knowing what devices are connected to the network, why those devices are connected to the network, and how those devices are individually configured. Otherwise, attackers can conduct old and innovative attacks without the organization’s knowledge by compromising that one insecure system.
Given how common these devices are, keeping IT in the loop may seem impossible — but we must rise to the challenge, ICIT says:
If a cyber network is a castle, then every insecure device with a connection to the internet is a secret passage that the adversary can exploit to infiltrate the network. Security systems are reactive. They have to know about something before they can recognize it. Modern systems already have difficulty preventing intrusion by slight variations of known malware. Most commercial security solutions such as firewalls, IDS/ IPS, and behavioral analytic systems function by monitoring where the attacker could attack the network and protecting those weakened points. The tools cannot protect systems that IT and the information security team are not aware exist.
The home environment – or any use outside the hospital setting – is another huge concern, says the report:
Remote monitoring devices could enable attackers to track the activity and health information of individuals over time. This possibility could impose a chilling effect on some patients. While the effect may lessen over time as remote monitoring technologies become normal, it could alter patient behavior enough to cause alarm and panic.
Pain medicine pumps and other devices that distribute controlled substances are likely high value targets to some attackers. If compromise of a system is as simple as downloading free malware to a USB and plugging the USB into the pump, then average drug addicts can exploit homecare and other vulnerable patients by fooling the monitors. One of the simpler mitigation strategies would be to combine remote monitoring technologies with sensors that aggregate activity data to match a profile of expected user activity.
A major responsibility falls onto the device makers – and the programmers who create the embedded software. For the most part, they are simply not up to the challenge of designing secure devices, and may not have the polices, practices and tools in place to get cybersecurity right. Regrettably, the ICIT report doesn’t go into much detail about the embedded software, but does state,
Unlike cell phones and other trendy technologies, embedded devices require years of research and development; sadly, cybersecurity is a new concept to many healthcare manufacturers and it may be years before the next generation of embedded devices incorporates security into its architecture. In other sectors, if a vulnerability is discovered, then developers rush to create and issue a patch. In the healthcare and embedded device environment, this approach is infeasible. Developers must anticipate what the cyber landscape will look like years in advance if they hope to preempt attacks on their devices. This model is unattainable.
In November 2015, Bloomberg Businessweek published a chilling story, “It’s Way too Easy to Hack the Hospital.” The authors, Monte Reel and Jordon Robertson, wrote about one hacker, Billy Rios:
Shortly after flying home from the Mayo gig, Rios ordered his first device—a Hospira Symbiq infusion pump. He wasn’t targeting that particular manufacturer or model to investigate; he simply happened to find one posted on EBay for about $100. It was an odd feeling, putting it in his online shopping cart. Was buying one of these without some sort of license even legal? he wondered. Is it OK to crack this open?
Infusion pumps can be found in almost every hospital room, usually affixed to a metal stand next to the patient’s bed, automatically delivering intravenous drips, injectable drugs, or other fluids into a patient’s bloodstream. Hospira, a company that was bought by Pfizer this year, is a leading manufacturer of the devices, with several different models on the market. On the company’s website, an article explains that “smart pumps” are designed to improve patient safety by automating intravenous drug delivery, which it says accounts for 56 percent of all medication errors.
Rios connected his pump to a computer network, just as a hospital would, and discovered it was possible to remotely take over the machine and “press” the buttons on the device’s touchscreen, as if someone were standing right in front of it. He found that he could set the machine to dump an entire vial of medication into a patient. A doctor or nurse standing in front of the machine might be able to spot such a manipulation and stop the infusion before the entire vial empties, but a hospital staff member keeping an eye on the pump from a centralized monitoring station wouldn’t notice a thing, he says.
The 97-page ICIT report makes some recommendations, which I heartily agree with.
- With each item connected to the internet of things there is a universe of vulnerabilities. Empirical evidence of aggressive penetration testing before and after a medical device is released to the public must be a manufacturer requirement.
- Ongoing training must be paramount in any responsible healthcare organization. Adversarial initiatives typically start with targeting staff via spear phishing and watering hole attacks. The act of an ill- prepared executive clicking on a malicious link can trigger a hurricane of immediate and long term negative impact on the organization and innocent individuals whose records were exfiltrated or manipulated by bad actors.
- A cybersecurity-centric culture must demand safer devices from manufacturers, privacy adherence by the healthcare sector as a whole and legislation that expedites the path to a more secure and technologically scalable future by policy makers.
This whole thing is scary. The healthcare industry needs to set up its game on cybersecurity.
 Agility – the ability to deliver projects quickly. That applies to new projects, as well as updates to existing projects. The agile software movement began when many smart people became frustrated with the classic model of development, where first the organization went through a complex process to develop requirements (which took months or years), and wrote software to address those requirements (which took months or years, or maybe never finished). By then, not only did the organization miss out on many opportunities, but perhaps the requirements were no longer valid – if they ever were.
Agility – the ability to deliver projects quickly. That applies to new projects, as well as updates to existing projects. The agile software movement began when many smart people became frustrated with the classic model of development, where first the organization went through a complex process to develop requirements (which took months or years), and wrote software to address those requirements (which took months or years, or maybe never finished). By then, not only did the organization miss out on many opportunities, but perhaps the requirements were no longer valid – if they ever were.
 The bad news: There are servers used in serverless computing. Real servers, with whirring fans and lots of blinking lights, installed in racks inside data centers inside the enterprise or up in the cloud.
The bad news: There are servers used in serverless computing. Real servers, with whirring fans and lots of blinking lights, installed in racks inside data centers inside the enterprise or up in the cloud. Those are two popular ways of migrating enterprise assets to the cloud:
Those are two popular ways of migrating enterprise assets to the cloud: About a decade ago, I purchased a piece of a mainframe on eBay — the name ID bar. Carved from a big block of aluminum, it says “
About a decade ago, I purchased a piece of a mainframe on eBay — the name ID bar. Carved from a big block of aluminum, it says “ To get the most benefit from the new world of cloud-native server applications, forget about the old way of writing software. In the old model, architects designed software. Programmers wrote the code, and testers tested it on test server. Once the testing was complete, the code was “thrown over the wall” to administrators, who installed the software on production servers, and who essentially owned the applications moving forward, only going back to the developers if problems occurred.
To get the most benefit from the new world of cloud-native server applications, forget about the old way of writing software. In the old model, architects designed software. Programmers wrote the code, and testers tested it on test server. Once the testing was complete, the code was “thrown over the wall” to administrators, who installed the software on production servers, and who essentially owned the applications moving forward, only going back to the developers if problems occurred. “One of these things is not like the others,” the television show Sesame Street taught generations of children. Easy. Let’s move to the next level: “One or more of these things may or may not be like the others, and those variances may or may not represent systems vulnerabilities, failed patches, configuration errors, compliance nightmares, or imminent hardware crashes.” That’s a lot harder than distinguishing cookies from brownies.
“One of these things is not like the others,” the television show Sesame Street taught generations of children. Easy. Let’s move to the next level: “One or more of these things may or may not be like the others, and those variances may or may not represent systems vulnerabilities, failed patches, configuration errors, compliance nightmares, or imminent hardware crashes.” That’s a lot harder than distinguishing cookies from brownies. IT managers shouldn’t have to choose between cloud-driven innovation and data-center-style computing. Developers shouldn’t have to choose between the latest DevOps programming using containers and microservices, and traditional architectures and methodologies. CIOs shouldn’t have to choose between a fully automated and fully managed cloud and a self-managed model using their own on-staff administrators.
IT managers shouldn’t have to choose between cloud-driven innovation and data-center-style computing. Developers shouldn’t have to choose between the latest DevOps programming using containers and microservices, and traditional architectures and methodologies. CIOs shouldn’t have to choose between a fully automated and fully managed cloud and a self-managed model using their own on-staff administrators. Despite
Despite  At the current rate of rainfall, when will your local reservoir overflow its banks? If you shoot a rocket at an angle of 60 degrees into a headwind, how far will it fly with 40 pounds of propellant and a 5-pound payload? Assuming a 100-month loan for $75,000 at 5.11 percent, what will the payoff balance be after four years? If a lab culture is doubling every 14 hours, how many viruses will there be in a week?
At the current rate of rainfall, when will your local reservoir overflow its banks? If you shoot a rocket at an angle of 60 degrees into a headwind, how far will it fly with 40 pounds of propellant and a 5-pound payload? Assuming a 100-month loan for $75,000 at 5.11 percent, what will the payoff balance be after four years? If a lab culture is doubling every 14 hours, how many viruses will there be in a week?
 It’s almost painful to see an issue of
It’s almost painful to see an issue of 
 The
The  “Someone is waiting just for you / Spinnin’ wheel, spinnin’ true.”
“Someone is waiting just for you / Spinnin’ wheel, spinnin’ true.”

 Can’t we fix injection already? It’s been nearly four years since the most recent iteration of the OWASP Top 10 came out — that’s June 12, 2013. The OWASP Top 10 are the most critical web application security flaws, as determined by a large group of experts. The list doesn’t change much, or change often, because the fundamentals of web application security are consistent.
Can’t we fix injection already? It’s been nearly four years since the most recent iteration of the OWASP Top 10 came out — that’s June 12, 2013. The OWASP Top 10 are the most critical web application security flaws, as determined by a large group of experts. The list doesn’t change much, or change often, because the fundamentals of web application security are consistent.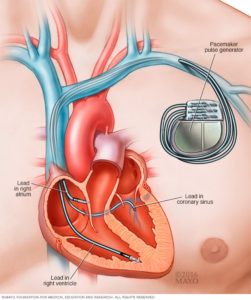 Modern medical devices increasingly leverage microprocessors and embedded software, as well as sophisticated communications connections, for life-saving functionality. Insulin pumps, for example, rely on a battery, pump mechanism, microprocessor, sensors, and embedded software. Pacemakers and cardiac monitors also contain batteries, sensors, and software. Many devices also have WiFi- or Bluetooth-based communications capabilities. Even hospital rooms with intravenous drug delivery systems are controlled by embedded microprocessors and software, which are frequently connected to the institution’s network. But these innovations also mean that a software defect can cause a critical failure or security vulnerability.
Modern medical devices increasingly leverage microprocessors and embedded software, as well as sophisticated communications connections, for life-saving functionality. Insulin pumps, for example, rely on a battery, pump mechanism, microprocessor, sensors, and embedded software. Pacemakers and cardiac monitors also contain batteries, sensors, and software. Many devices also have WiFi- or Bluetooth-based communications capabilities. Even hospital rooms with intravenous drug delivery systems are controlled by embedded microprocessors and software, which are frequently connected to the institution’s network. But these innovations also mean that a software defect can cause a critical failure or security vulnerability. The best way to have a butt-kicking cloud-native application is to write one from scratch. Leverage the languages, APIs, and architecture of the chosen cloud platform before exploiting its databases, analytics engines, and storage. As I wrote for Ars Technica, this will allow you to take advantage of the wealth of resources offered by companies like Microsoft, with their Azure PaaS (Platform-as-a-Service) offering or by Google Cloud Platform’s Google App Engine PaaS service.
The best way to have a butt-kicking cloud-native application is to write one from scratch. Leverage the languages, APIs, and architecture of the chosen cloud platform before exploiting its databases, analytics engines, and storage. As I wrote for Ars Technica, this will allow you to take advantage of the wealth of resources offered by companies like Microsoft, with their Azure PaaS (Platform-as-a-Service) offering or by Google Cloud Platform’s Google App Engine PaaS service. Las Vegas, January 2017 — “
Las Vegas, January 2017 — “ According to a recent study, 46% of the top one million websites are considered risky. Why? Because the homepage or background ad sites are running software with known vulnerabilities, the site was categorized as a known bad for phishing or malware, or the site had a security incident in the past year.
According to a recent study, 46% of the top one million websites are considered risky. Why? Because the homepage or background ad sites are running software with known vulnerabilities, the site was categorized as a known bad for phishing or malware, or the site had a security incident in the past year. For programmers, a language style guide is essential for helping learn a language’s standards. A style guide also can resolve potential ambiguities in syntax and usage. Interestingly, though, the official
For programmers, a language style guide is essential for helping learn a language’s standards. A style guide also can resolve potential ambiguities in syntax and usage. Interestingly, though, the official 
 Be paranoid! When you visit a website for the first time, it can learn a lot about you. If you have cookies on your computer from one of the site’s partners, it can see what else you have been doing. And it can place cookies onto your computer so it can track your future activities.
Be paranoid! When you visit a website for the first time, it can learn a lot about you. If you have cookies on your computer from one of the site’s partners, it can see what else you have been doing. And it can place cookies onto your computer so it can track your future activities. Are you a coder? Architect? Database guru? Network engineer? Mobile developer? User-experience expert? If you have hands-on tech skills, get those hands dirty at a Hackathon.
Are you a coder? Architect? Database guru? Network engineer? Mobile developer? User-experience expert? If you have hands-on tech skills, get those hands dirty at a Hackathon. What’s it going to mean for Java? When Oracle purchased Sun Microsystems that was one of the biggest questions on the minds of many software developers, and indeed, the entire industry. In an April 2009 blog post, “
What’s it going to mean for Java? When Oracle purchased Sun Microsystems that was one of the biggest questions on the minds of many software developers, and indeed, the entire industry. In an April 2009 blog post, “ The newest issue of the second-best software development publication is out – and it’s a doozy. You’ll definitely want to read the July/August 2016 issue of
The newest issue of the second-best software development publication is out – and it’s a doozy. You’ll definitely want to read the July/August 2016 issue of  When it comes to cars, safety means more than strong brakes, good tires, a safety cage, and lots of airbags. It also means software that won’t betray you; software that doesn’t pose a risk to life and property; software that’s working for you, not for a hacker.
When it comes to cars, safety means more than strong brakes, good tires, a safety cage, and lots of airbags. It also means software that won’t betray you; software that doesn’t pose a risk to life and property; software that’s working for you, not for a hacker. Scammers give local businesses a faux award and then try to make money by selling certificates, trophies, and so-on.
Scammers give local businesses a faux award and then try to make money by selling certificates, trophies, and so-on. I wrote five contributions for an ebook from AMD Developer Central — and forgot entirely about it! The book, called “
I wrote five contributions for an ebook from AMD Developer Central — and forgot entirely about it! The book, called “