 Excellent story about SharePoint in ComputerWorld this week. It gives encouragement to those who prefer to run SharePoint in their own data centers (on-premises), rather than in the cloud. In “The Future of SharePoint,” Brian Alderman writes,
Excellent story about SharePoint in ComputerWorld this week. It gives encouragement to those who prefer to run SharePoint in their own data centers (on-premises), rather than in the cloud. In “The Future of SharePoint,” Brian Alderman writes,
In case you missed it, on May 4 Microsoft made it loud and clear it has resuscitated SharePoint On-Premises and there will be future versions, even beyond SharePoint Server 2016. However, by making you aware of the scenarios most appropriate for On-Premises and the scenarios where you can benefit from SharePoint Online, Microsoft is going to remain adamant about allowing you to create the perfect SharePoint hybrid deployment.
The future of SharePoint begins with SharePoint Online, meaning changes, features and functionality will first be deployed to SharePoint Online, and then rolled out to your SharePoint Server On-Premises deployment. This approach isn’t much of a surprise, being that SharePoint Server 2016 On-Premises was “engineered” from SharePoint Online.
Brian was writing about a post on the Microsoft SharePoint blog, and one I had overlooked (else I’d have written about it back in May. In the post, “SharePoint Server 2016—your foundation for the future,” the SharePoint Team says,
We remain committed to our on-premises customers and recognize the need to modernize experiences, patterns and practices in SharePoint Server. While our innovation will be delivered to Office 365 first, we will provide many of the new experiences and frameworks to SharePoint Server 2016 customers with Software Assurance through Feature Packs. This means you won’t have to wait for the next version of SharePoint Server to take advantage of our cloud-born innovation in your datacenter.
The first Feature Pack will be delivered through our public update channel starting in calendar year 2017, and customers will have control over which features are enabled in their on-premises farms. We will provide more detail about our plans for Feature Packs in coming months.
In addition, we will deliver a set of capabilities for SharePoint Server 2016 that address the unique needs of on-premises customers.
Now, make no mistake: The emphasis at Microsoft is squarely on Office 365 and SharePoint Online. Or as the company says SharePoint Server is, “powering your journey to the mobile-first, cloud-first world.” However, it is clear that SharePoint On-Premises will continue for some period of time. Later in the blog post in the FAQ, this is stated quite definitively:
Is SharePoint Server 2016 the last server release?
No, we remain committed to our customer’s on-premises and do not consider SharePoint Server 2016 to be the last on-premises server release.
The best place to learn about SharePoint 2016 is at BZ Media’s SPTechCon, returning to San Francisco from Dec. 5-8. (I am the Z of BZ Media.) SPTechCon, the SharePoint Technology Conference, offers more than 80 technical classes and tutorials — presented by the most knowledgeable instructors working in SharePoint today — to help you improve your skills and broaden your knowledge of Microsoft’s collaboration and productivity software.
SPTechCon will feature the first conference sessions on SharePoint 2016. Be there! Learn more at http://www.sptechcon.com.
 Was it a software failure? The recent fatal crash of a Tesla in Autopilot mode is worrisome, but it’s too soon to blame Tesla’s software.
Was it a software failure? The recent fatal crash of a Tesla in Autopilot mode is worrisome, but it’s too soon to blame Tesla’s software. 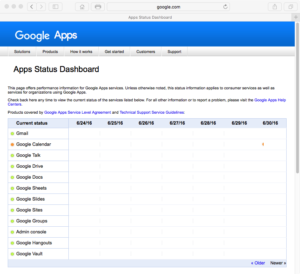 Cloud services crash. Of course, non-cloud-services crash too — a server in your data center can go down, too. At least there you can do something, or if it’s a critical system you can plan with redundancies and failover.
Cloud services crash. Of course, non-cloud-services crash too — a server in your data center can go down, too. At least there you can do something, or if it’s a critical system you can plan with redundancies and failover. The MEF recently conducted its second LSO Hackathon at a Rome event called Euro16. You can read my story about it here in DiarioTi:
The MEF recently conducted its second LSO Hackathon at a Rome event called Euro16. You can read my story about it here in DiarioTi:  I can hear the protesters. “What do we want? Faster automated emails! When do we want them? In under 20 nanoseconds!”
I can hear the protesters. “What do we want? Faster automated emails! When do we want them? In under 20 nanoseconds!” Despite some recent progress, women are still woefully underrepresented in technical fields such as software development. There are many academic programs to bring girls into STEM (science, technology, engineering and math) at various stages in their education, from grade school to high school to college. Corporations are trying hard.
Despite some recent progress, women are still woefully underrepresented in technical fields such as software development. There are many academic programs to bring girls into STEM (science, technology, engineering and math) at various stages in their education, from grade school to high school to college. Corporations are trying hard. It’s not intellectual property. It’s not having code warriors who can turn pizza into algorithms. It’s not even having great angel investors. If you want a successful startup that’s going to keep you in the headlines for your technology and market prowess, you need a great Human Resources department.
It’s not intellectual property. It’s not having code warriors who can turn pizza into algorithms. It’s not even having great angel investors. If you want a successful startup that’s going to keep you in the headlines for your technology and market prowess, you need a great Human Resources department. Today’s serendipitous discovery: A blog post about the Enterprise Software Development Conference (ESC), produced by
Today’s serendipitous discovery: A blog post about the Enterprise Software Development Conference (ESC), produced by 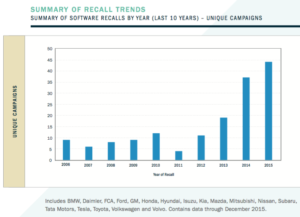
 I once designed and coded a campus parking pass management system for an East Coast university. If you had a faculty, staff, student or visitor parking sticker for the campus, it was processed using my green-screen application, which went online in 1983. The university used the mainframe program with minimal changes for about a decade, until a new client/server parking system was implemented.
I once designed and coded a campus parking pass management system for an East Coast university. If you had a faculty, staff, student or visitor parking sticker for the campus, it was processed using my green-screen application, which went online in 1983. The university used the mainframe program with minimal changes for about a decade, until a new client/server parking system was implemented. Fire up the
Fire up the  San Francisco – Apple’s
San Francisco – Apple’s  I am hoovering directly from the blog of my friend
I am hoovering directly from the blog of my friend  No smart software would make the angry customer less angry. No customer relationship management platform could understand the problem. No sophisticated
No smart software would make the angry customer less angry. No customer relationship management platform could understand the problem. No sophisticated  Let’s explore the causes of slow website loads. There are obviously some delays that are beyond our control — like the user being on a very slow mobile connection. However, for the most part, our website’s load time is entirely up to us.
Let’s explore the causes of slow website loads. There are obviously some delays that are beyond our control — like the user being on a very slow mobile connection. However, for the most part, our website’s load time is entirely up to us. Barcelona, Mobile World Congress 2016—IoT success isn’t about device features, like long-life batteries, factory-floor sensors and snazzy designer wristbands. The real power, the real value, of the Internet of Things is in the data being transmitted from devices to remote servers, and from those remote servers back to the devices.
Barcelona, Mobile World Congress 2016—IoT success isn’t about device features, like long-life batteries, factory-floor sensors and snazzy designer wristbands. The real power, the real value, of the Internet of Things is in the data being transmitted from devices to remote servers, and from those remote servers back to the devices. A hackathon – like the debut
A hackathon – like the debut 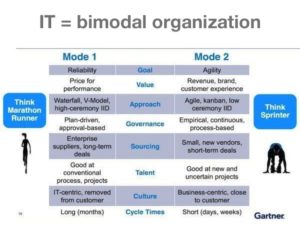 Las Vegas, December 2015 — Get ready for Bimodal IT. That’s the message from the
Las Vegas, December 2015 — Get ready for Bimodal IT. That’s the message from the  Your app’s user interface is terrible. Your business plan is flawed. Your budget is a pipe dream. Your code isn’t efficient. Clients are unhappy with your interpersonal skills. Your meetings are too long. You don’t seem to get along with your developers. You are hard to work with. You are being kicked off the task force because you aren’t adding any value. The tone of your e-mail was too informal. Your department is being given to someone else. No, we won’t need you for this project. No, we don’t need you at all.
Your app’s user interface is terrible. Your business plan is flawed. Your budget is a pipe dream. Your code isn’t efficient. Clients are unhappy with your interpersonal skills. Your meetings are too long. You don’t seem to get along with your developers. You are hard to work with. You are being kicked off the task force because you aren’t adding any value. The tone of your e-mail was too informal. Your department is being given to someone else. No, we won’t need you for this project. No, we don’t need you at all. Software-defined networks and Network Functions Virtualization will redefine enterprise computing and change the dynamics of the cloud. Data thefts and professional hacks will grow, and development teams will shift their focus from adding new features to hardening against attacks. Those are two of my predictions for 2015.
Software-defined networks and Network Functions Virtualization will redefine enterprise computing and change the dynamics of the cloud. Data thefts and professional hacks will grow, and development teams will shift their focus from adding new features to hardening against attacks. Those are two of my predictions for 2015.
 SEYTON
SEYTON Malicious agents can crash a website by implementing a DDoS—a Distributed Denial of Service Attack—against a server. So can sloppy programmers.
Malicious agents can crash a website by implementing a DDoS—a Distributed Denial of Service Attack—against a server. So can sloppy programmers.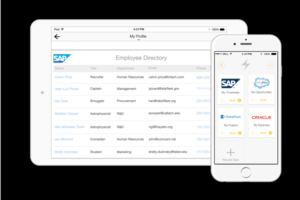 HTML browser virtualization, not APIs, may be the best way to mobilize existing enterprise applications like SAP ERP, Oracle E-Business Suite or Microsoft Dynamics.
HTML browser virtualization, not APIs, may be the best way to mobilize existing enterprise applications like SAP ERP, Oracle E-Business Suite or Microsoft Dynamics. You’ve gotta read “
You’ve gotta read “ Thirty seconds. That’s about how long a mobile user will spend with your game before deciding if he or she will continue using it. Thirty seconds. Maybe a minute. If you haven’t engaged the customer by then, forget it.
Thirty seconds. That’s about how long a mobile user will spend with your game before deciding if he or she will continue using it. Thirty seconds. Maybe a minute. If you haven’t engaged the customer by then, forget it. First Impressions of the
First Impressions of the