 Cloud-based development tools are great. Until they don’t work.
Cloud-based development tools are great. Until they don’t work.
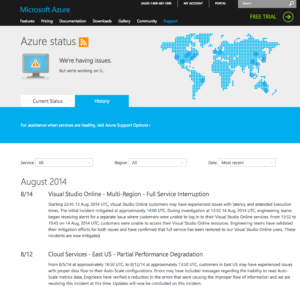
I don’t know if you were affected by Microsoft’s Azure service outage on Thursday, August 14, 2014. As of my deadline, services had been offline for nearly six hours. On its status page, Microsoft was reporting:
Visual Studio Online – Multi-Region – Full Service Interruption
Starting 22:45 13 Aug, 2014 UTC, Visual Studio Online customers may have experienced issues with latency and extended Execution times. The initial incident mitigated at approximately 14:00 UTC. During investigation at 13:52 14 Aug, 2014 UTC, engineering teams began receiving alerts for a separate issue where customers were unable to log in to their Visual Studio Online services. From 13:52 to 19:45 on 14 Aug, 2014 UTC, customers were unable to access their Visual Studio Online resources. Engineering teams have validated their mitigation efforts for both issues and have confirmed that full service has been restored to our Visual Studio Online users. These incidents are now mitigated.
My goal here isn’t to throw Microsoft under the bus. Azure has been quite stable, and other cloud providers, including Amazon, Apple and Google, have seen similar problems. Actually, Amazon in particular has seen a lot of uptime and stability problems with AWS over the past couple of years, though its dashboard on Thursday afternoon shows full service availability.
Let’s think about the broader issue. What’s your contingency plan if your cloud-based services go down, whether it’s one of those players, or a service like GitHub, Salesforce.com, SourceForge, or you-name-it? Do you have backups, in case code or artifacts are lost or corrupted? (Do you have any way to know if data is lost or corrupted?)
This is a worry.
In the case of the August 14 outage, the system wasn’t down for long — but long enough to kill a day’s productivity for many workers. Microsoft’s Visual Studio Online blog has a little bit of insight into the problem, but not much. Posted at 16:56 UTC, Microsoft said:
The actual root cause is still under investigation, but initial investigation is indicating a contention in our core database seems to be causing blocking and performance issues in the services. Our DevOps teams have identified a couple of mitigation steps and currently going thru validations. We will provide an update as soon as we have a mitigation in place. We apologize for the inconvenience and appreciate your patience while working on resolving this issue
This time you can blame Microsoft for any loss of productivity. Next time the service goes down, if you haven’t made contingency plans, the blame is yours.