 Loose cyber-lips can sink real ship. According to separate reports published by the British government and the cruise ship industry, large cargo and passenger vessels could be damaged by cyberattacks – and potentially even sent to the bottom of the ocean.
Loose cyber-lips can sink real ship. According to separate reports published by the British government and the cruise ship industry, large cargo and passenger vessels could be damaged by cyberattacks – and potentially even sent to the bottom of the ocean.
The foreword pulls no punches. “Code of Practice: Cyber Security for Ships” was commissioned by the U.K. Department of Transport, and published by the Institution of Engineering and Technology (IET) in London.
Poor security could lead to significant loss of customer and/or industry confidence, reputational damage, potentially severe financial losses or penalties, and litigation affecting the companies involved. The compromise of ship systems may also lead to unwanted outcomes, for example:
(a) physical harm to the system or the shipboard personnel or cargo – in the worst case scenario this could lead to a risk to life and/or the loss of the ship;
(b) disruptions caused by the ship no longer functioning or sailing as intended;
(c) loss of sensitive information, including commercially sensitive or personal data;
and
(d) permitting criminal activity, including kidnap, piracy, fraud, theft of cargo, imposition of ransomware.
The above scenarios may occur at an individual ship level or at fleet level; the latter is likely to be much worse and could severely disrupt fleet operations.
Cargo and Passenger Systems
The report goes into considerable detail about the need to protect confidential information, including intellectual property, cargo manifests, passenger lists, and financial documents. Beyond that, the document warns about dangers from activist groups (or “hackivism”) where actors might work to prevent the handling of specific cargoes, or even disrupt the operation of the ship. The target may be the ship itself, the ship’s owner or operator, or the supplier or recipient of the cargo.
The types of damage could be as simple as the disruption of ship-to-shore communications through a DDoS attack. It might be as dangerous as the corruption or feeding false sensor data that could cause the vessel to flounder or head off course. What can done? The reports several important steps to maintain the security of critical systems including:
(a) Confidentiality – the control of access and prevention of unauthorised access to ship data, which might be sensitive in isolation or in aggregate. The ship systems and associated processes should be designed, implemented, operated and maintained so as to prevent unauthorised access to, for example, sensitive financial, security, commercial or personal data. All personal data should be handled in accordance with the Data Protection Act and additional measures may be required to protect privacy due to the aggregation of data, information or metadata.
(b) Possession and/or control – the design, implementation, operation and maintenance of ship systems and associated processes so as to prevent unauthorised control, manipulation or interference. The ship systems and associated processes should be designed, implemented, operated and maintained so as to prevent unauthorised control, manipulation or interference. An example would be the loss of an encrypted storage device – there is no loss of confidentiality as the information is inaccessible without the encryption key, but the owner or user is deprived of its contents.
(c) Integrity – maintaining the consistency, coherence and configuration of information and systems, and preventing unauthorised changes to them. The ship systems and associated processes should be designed, implemented, operated and maintained so as to prevent unauthorised changes being made to assets, processes, system state or the configuration of the system itself. A loss of system integrity could occur through physical changes to a system, such as the unauthorised connection of a Wi-Fi access point to a secure network, or through a fault such as the corruption of a database or file due to media storage errors.
(d) Authenticity – ensuring that inputs to, and outputs from, ship systems, the state of the systems and any associated processes and ship data, are genuine and have not been tampered with or modified. It should also be possible to verify the authenticity of components, software and data within the systems and any associated processes. Authenticity issues could relate to data such as a forged security certificate or to hardware such as a cloned device.
With passenger vessels, the report points for the need for modular controls and hardened IT infrastructure. That stops unauthorized people from gaining access to online booking, point-of-sales, passenger management, and other critical ships systems by tapping into wiring cabinets, cable junctions, and maintenance areas. Like we said, scary stuff.
The Industry Weighs In
A similar report was produced for the shipping industry by seven organizations, including the International Maritime Organization and the International Chamber of Shipping. The “Guidelines on Cyber Security Onboard Ships” warns that that incident can arise as the result of,
- A cyber security incident, which affects the availability and integrity of OT, for example corruption of chart data held in an Electronic Chart Display and Information System (ECDIS)
- A failure occurring during software maintenance and patching
- Loss of or manipulation of external sensor data, critical for the operation of a ship. This includes but is not limited to Global Navigation Satellite Systems (GNSS).
This report discusses the role of activists (including disgruntles employees), as well as criminals, opportunists, terrorists, and state-sponsored organizations. There are many potentially vulnerable areas, including cargo management systems, bridge systems, propulsion and other machinery, access control, passenger management systems — and communications. As the report says,
Modern technologies can add vulnerabilities to the ships especially if there are insecure designs of networks and uncontrolled access to the internet. Additionally, shoreside and onboard personnel may be unaware how some equipment producers maintain remote access to shipboard equipment and its network system. The risks of misunderstood, unknown, and uncoordinated remote access to an operating ship should be taken into consideration as an important part of the risk assessment.
The stakes are high. The loss of operational technology (OT) systems “may have a significant and immediate impact on the safe operation of the ship. Should a cyber incident result in the loss or malfunctioning of OT systems, it will be essential that effective actions are taken to ensure the immediate safety of the crew, ship and protection of the marine environment.”
Sobering words for any maritime operator.
 You want to read Backlinko’s “The Definitive Guide To SEO In 2018.” Backlinko is an SEO consultancy founded by Brian Dean. The “Definitive Guide” is a cheerfully illustrated infographic – a lengthy infographic – broken up into several useful chapters:
You want to read Backlinko’s “The Definitive Guide To SEO In 2018.” Backlinko is an SEO consultancy founded by Brian Dean. The “Definitive Guide” is a cheerfully illustrated infographic – a lengthy infographic – broken up into several useful chapters: Our family’s Halloween tradition: Watch “
Our family’s Halloween tradition: Watch “ What happens when the sun goes disappears during the daytime? Rabbi Margaret Frisch Klein, of Congregation Kneseth Israel in Elgin, Illinois, wrote in her Energizer Rabbi blog on Aug. 22, 2017, just before the solar eclipse:
What happens when the sun goes disappears during the daytime? Rabbi Margaret Frisch Klein, of Congregation Kneseth Israel in Elgin, Illinois, wrote in her Energizer Rabbi blog on Aug. 22, 2017, just before the solar eclipse: Apply patches. Apply updates. Those are considered to be among the lowest-hanging of the low-hanging fruit for IT cybersecurity. When commercial products release patches, download and install the code right away. When open-source projects disclose a vulnerability, do the appropriate update as soon as you can, everyone says.
Apply patches. Apply updates. Those are considered to be among the lowest-hanging of the low-hanging fruit for IT cybersecurity. When commercial products release patches, download and install the code right away. When open-source projects disclose a vulnerability, do the appropriate update as soon as you can, everyone says. You can call me Ray, or you can call me Jay, or you can call me Johnny or you can call me Sonny, or you can call me RayJay, or you can call me RJ… but ya doesn’t hafta call me Johnson.
You can call me Ray, or you can call me Jay, or you can call me Johnny or you can call me Sonny, or you can call me RayJay, or you can call me RJ… but ya doesn’t hafta call me Johnson. This is a common scam: The scammer pretends to be a famous person, and links to the bio or a story about that person. That means nothing. A person wants to share some gold with you, and links to a BBC story about a battle in Iraq or Afghanistan. That means nothing. A person claims to be one of the members of the wealthy family that owns Wal-Mart, with links to a Wikipedia page. That means nothing.
This is a common scam: The scammer pretends to be a famous person, and links to the bio or a story about that person. That means nothing. A person wants to share some gold with you, and links to a BBC story about a battle in Iraq or Afghanistan. That means nothing. A person claims to be one of the members of the wealthy family that owns Wal-Mart, with links to a Wikipedia page. That means nothing. Open source software (OSS) offers many benefits for organizations large and small—not the least of which is the price tag, which is often zero. Zip. Nada. Free-as-in-beer. Beyond that compelling price tag, what you often get with OSS is a lack of a hidden agenda. You can see the project, you can see the source code, you can see the communications, you can see what’s going on in the support forums.
Open source software (OSS) offers many benefits for organizations large and small—not the least of which is the price tag, which is often zero. Zip. Nada. Free-as-in-beer. Beyond that compelling price tag, what you often get with OSS is a lack of a hidden agenda. You can see the project, you can see the source code, you can see the communications, you can see what’s going on in the support forums. For no particular reason, and in alphabetical order, my favorite episodes from the original Star Trek, aka, The Original Series.
For no particular reason, and in alphabetical order, my favorite episodes from the original Star Trek, aka, The Original Series. Those are two popular ways of migrating enterprise assets to the cloud:
Those are two popular ways of migrating enterprise assets to the cloud: I can’t believe my luck – Microsoft co-founder Bill Gates wants to give me $5 million. Hurray! And not only that, he’s contacting me from an email address at Nelson Mandela University in South Africa. It’s also a shame to learn that he’s sick and is going to Germany for treatment.
I can’t believe my luck – Microsoft co-founder Bill Gates wants to give me $5 million. Hurray! And not only that, he’s contacting me from an email address at Nelson Mandela University in South Africa. It’s also a shame to learn that he’s sick and is going to Germany for treatment. About a decade ago, I purchased a piece of a mainframe on eBay — the name ID bar. Carved from a big block of aluminum, it says “
About a decade ago, I purchased a piece of a mainframe on eBay — the name ID bar. Carved from a big block of aluminum, it says “ To get the most benefit from the new world of cloud-native server applications, forget about the old way of writing software. In the old model, architects designed software. Programmers wrote the code, and testers tested it on test server. Once the testing was complete, the code was “thrown over the wall” to administrators, who installed the software on production servers, and who essentially owned the applications moving forward, only going back to the developers if problems occurred.
To get the most benefit from the new world of cloud-native server applications, forget about the old way of writing software. In the old model, architects designed software. Programmers wrote the code, and testers tested it on test server. Once the testing was complete, the code was “thrown over the wall” to administrators, who installed the software on production servers, and who essentially owned the applications moving forward, only going back to the developers if problems occurred. “One of these things is not like the others,” the television show Sesame Street taught generations of children. Easy. Let’s move to the next level: “One or more of these things may or may not be like the others, and those variances may or may not represent systems vulnerabilities, failed patches, configuration errors, compliance nightmares, or imminent hardware crashes.” That’s a lot harder than distinguishing cookies from brownies.
“One of these things is not like the others,” the television show Sesame Street taught generations of children. Easy. Let’s move to the next level: “One or more of these things may or may not be like the others, and those variances may or may not represent systems vulnerabilities, failed patches, configuration errors, compliance nightmares, or imminent hardware crashes.” That’s a lot harder than distinguishing cookies from brownies. AOL Instant Messenger will be dead before the end of 2017. Yet, instant messages have succeeded far beyond what anyone could have envisioned for either SMS (Short Message Service, carried by the phone company) or AOL, which arguably brought instant messaging to regular computers starting in 1997.
AOL Instant Messenger will be dead before the end of 2017. Yet, instant messages have succeeded far beyond what anyone could have envisioned for either SMS (Short Message Service, carried by the phone company) or AOL, which arguably brought instant messaging to regular computers starting in 1997.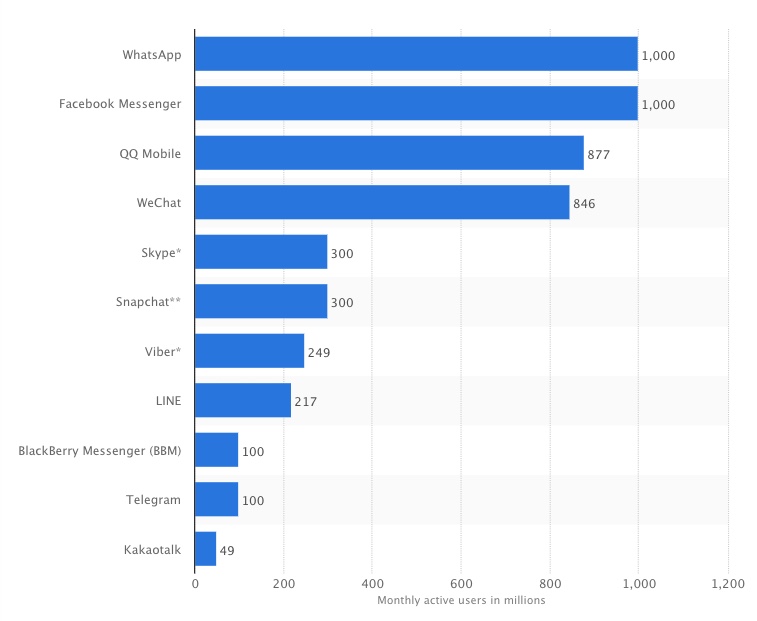
 IT managers shouldn’t have to choose between cloud-driven innovation and data-center-style computing. Developers shouldn’t have to choose between the latest DevOps programming using containers and microservices, and traditional architectures and methodologies. CIOs shouldn’t have to choose between a fully automated and fully managed cloud and a self-managed model using their own on-staff administrators.
IT managers shouldn’t have to choose between cloud-driven innovation and data-center-style computing. Developers shouldn’t have to choose between the latest DevOps programming using containers and microservices, and traditional architectures and methodologies. CIOs shouldn’t have to choose between a fully automated and fully managed cloud and a self-managed model using their own on-staff administrators. Despite
Despite