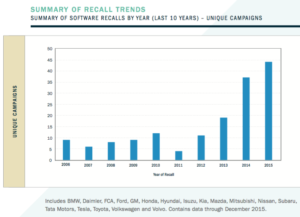
Summary of Recall Trends. Source: SRR.
The costs of an automobile recall can be immense for an OEM automobile or light truck manufacturer – and potentially ruinous for a member of the industry’s supply chain. Think about the ongoing Takata airbag scandal, which Bloomberg says could cost US$24 billion. General Motors’ ignition locks recall may have reached $4.1 billion. In 2001, the exploding Firestone tires on the Ford Explorer cost $3 billion to recall. The list goes on and on. That’s all about hardware problems. What about bits and bytes?
Until now, it’s been difficult to quantify the impact of software defects on the automotive industry. Thanks to a new analysis from SRR called “Industry Insights for the Road Ahead: Automotive Warranty and Recall Report 2016,” we have a good handle on this elusive area.
According to the report, there were 63 software- related vehicle recalls from late 2012 to June 2015. That’s based on data from the United States’ National Highway Traffic Safety Administration (NHTSA). The SRR report derived that count of 63 software-related recalls using this methodology (p. 22),
To classify a recall as a software component recall, SRR searched the “Defect Summary” and “Corrective Action” fields of NHTSA’s Recall flat file for the term “software.” SRR’s inquiry captured descriptions of software-related defects identified specifically as such, as well as defects that were to be fixed by updating or changing a vehicle’s software.
That led to this analysis (p. 22),
Since the end of 2012, there has been a marked increase in recall activity due to software issues. For the primary light vehicle makes and models we studied, 32 unique software-related recalls affected about 3.6 million vehicles from 2005–2012. However, in a much shorter time period from the end of 2012 to June 2015, there were 63 software-related recalls affecting 6.4 million more vehicles.
And continuing (p. 23),
From less than 5 percent of all recalls in 2011, software-related recalls have risen to almost 15 percent in 2015. Overall, the amount of unique campaigns involving software has climbed dramatically, with nine times as many in 2015 than in 2011…
No surprises there given the dramatically increased complexity of today’s connected vehicles, with sophisticated internal networks, dozens of ECUs (electronic control units with microprocessors, memory, software and network connections), and extensive remote connectivity.
These software defects are not occurring only in systems where one expects to find sophisticated microprocessors and software, such as engine management controls and Internet-connected entertainment platforms. Microprocessors are being used to analyze everything from the driver’s position and stage of alert, to road hazards, to lane changes — and offer advanced features such as automatic parallel parking.
Where in the car are the software-related vehicle recalls? Since 2006, says the report, recalls have been prompted by defects in areas as diverse as locks/latches, power train, fuel system, vehicle speed control, air bags, electrical systems, engine and engine cooling, exterior lighting, steering, hybrid propulsion – and even the parking brake system.
That’s not all — because not every software defect results in a public and costly recall. That’s the last resort, from the OEM’s perspective. Whenever possible, the defects are either ignored by the vehicle manufacturer, or quietly addressed by a software update next time the car visits a dealer. (If the car doesn’t visit an official dealer for service, the owner may never know that a software update is available.) Says the report (p. 25),
In addition, SRR noted an increase in software-related Technical Service Bulletins (TSB), which identify issues with specific components, yet stop short of a recall. TSBs are issued when manufacturers provide recommended procedures to dealerships’ service departments for fixing problematic components.
A major role of the NHTSA is to record and analyze vehicle failures, and attempt to determine the cause. Not all failures result in a recall, or even in a TSB. However, they are tracked by the agency via Early Warning Reporting (EWR). Explains the report (p. 26),
In 2015, three new software-related categories reported data for the first time:
• Automatic Braking, listed on 21 EWR reports, resulting in 26 injuries and 1 fatality
• Electronic Stability, listed on 6 EWR reports, resulting in 7 injuries and 1 fatality
• Forward Collision Avoidance, listed in 1 EWR report, resulting in 1 injury and no fatalities
The bottom line here, beyond protecting life and property, is the bottom line for the automobile and its supply chain. As the report says in its conclusion (p. 33),
Suppliers that help OEMs get the newest software-aided components to market should be prepared for the increased financial exposure they could face if these parts fail.
About the Report
Industry Insights for the Road Ahead: Automotive Warranty and Recall Report 2016” was published by SRR: Stout, Risius Ross, which offers global financial advisory services. SRR has been in the automotive industry for 25 years, and says, “SRR professionals have more automotive experience in these service areas than any other advisory firm, period.”
This brilliant report — which is free to download in its entirety — was written by Neil Steinkamp, a Managing Director at SRR. He has extensive experience in providing a broad range of business and financial advice to corporate executives, risk managers, in-house counsel and trial lawyers. Mr. Steinkamp has provided consulting services and has been engaged as an expert in numerous matters involving automotive warranty and recall costs. His practice also includes consulting services for automotive OEMs, suppliers and their advisors regarding valuation, transactions and disputes.



 Medical devices are incredibly vulnerable to hacking attacks. In some cases it’s because of software defects that allow for exploits, like buffer overflows, SQL injection or insecure direct object references. In other cases, you can blame misconfigurations, lack of encryption (or weak encryption), non-secure data/control networks, unfettered wireless access, and worse.
Medical devices are incredibly vulnerable to hacking attacks. In some cases it’s because of software defects that allow for exploits, like buffer overflows, SQL injection or insecure direct object references. In other cases, you can blame misconfigurations, lack of encryption (or weak encryption), non-secure data/control networks, unfettered wireless access, and worse. When it comes to cars, safety means more than strong brakes, good tires, a safety cage, and lots of airbags. It also means software that won’t betray you; software that doesn’t pose a risk to life and property; software that’s working for you, not for a hacker.
When it comes to cars, safety means more than strong brakes, good tires, a safety cage, and lots of airbags. It also means software that won’t betray you; software that doesn’t pose a risk to life and property; software that’s working for you, not for a hacker. There are standards for everything, it seems. And those of us who work on Internet things are often amused (or bemused) by what comes out of the
There are standards for everything, it seems. And those of us who work on Internet things are often amused (or bemused) by what comes out of the  Was it a software failure? The recent fatal crash of a Tesla in Autopilot mode is worrisome, but it’s too soon to blame Tesla’s software.
Was it a software failure? The recent fatal crash of a Tesla in Autopilot mode is worrisome, but it’s too soon to blame Tesla’s software.  Cloud services crash. Of course, non-cloud-services crash too — a server in your data center can go down, too. At least there you can do something, or if it’s a critical system you can plan with redundancies and failover.
Cloud services crash. Of course, non-cloud-services crash too — a server in your data center can go down, too. At least there you can do something, or if it’s a critical system you can plan with redundancies and failover. I can hear the protesters. “What do we want? Faster automated emails! When do we want them? In under 20 nanoseconds!”
I can hear the protesters. “What do we want? Faster automated emails! When do we want them? In under 20 nanoseconds!” Today’s serendipitous discovery: A blog post about the Enterprise Software Development Conference (ESC), produced by
Today’s serendipitous discovery: A blog post about the Enterprise Software Development Conference (ESC), produced by  I am hoovering directly from the blog of my friend
I am hoovering directly from the blog of my friend  No smart software would make the angry customer less angry. No customer relationship management platform could understand the problem. No sophisticated
No smart software would make the angry customer less angry. No customer relationship management platform could understand the problem. No sophisticated 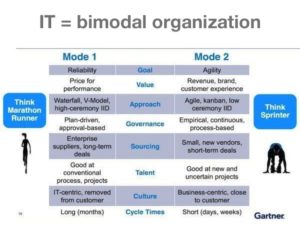 Las Vegas, December 2015 — Get ready for Bimodal IT. That’s the message from the
Las Vegas, December 2015 — Get ready for Bimodal IT. That’s the message from the  Malicious agents can crash a website by implementing a DDoS—a Distributed Denial of Service Attack—against a server. So can sloppy programmers.
Malicious agents can crash a website by implementing a DDoS—a Distributed Denial of Service Attack—against a server. So can sloppy programmers. Two consulting projects this year have involved lots and lots of data. One was the migration of a very complex customer database and transaction logging system to a cloud-based CRM platform from a homegrown system. The other involved performing serious analytics on a non-profit’s membership system that had data spanning decades.
Two consulting projects this year have involved lots and lots of data. One was the migration of a very complex customer database and transaction logging system to a cloud-based CRM platform from a homegrown system. The other involved performing serious analytics on a non-profit’s membership system that had data spanning decades. South San Francisco, California — Writing software would be oh, so much simpler if we didn’t have all those darned choices. HTML5 or native apps? Windows Server in the data center or Windows Azure in the cloud? Which Linux distro? Java or C#? Continuous Integration? Continuous Delivery? Git or Subversion or both? NoSQL? Which APIs? Node.js? Follow-the-sun?
South San Francisco, California — Writing software would be oh, so much simpler if we didn’t have all those darned choices. HTML5 or native apps? Windows Server in the data center or Windows Azure in the cloud? Which Linux distro? Java or C#? Continuous Integration? Continuous Delivery? Git or Subversion or both? NoSQL? Which APIs? Node.js? Follow-the-sun?



 If there’s no news… well, let’s make some up. That’s my thought upon reading all the stories about Apple’s forthcoming iWatch – a product that, as far as anyone knows, doesn’t exist.
If there’s no news… well, let’s make some up. That’s my thought upon reading all the stories about Apple’s forthcoming iWatch – a product that, as far as anyone knows, doesn’t exist.

