 Medical devices are incredibly vulnerable to hacking attacks. In some cases it’s because of software defects that allow for exploits, like buffer overflows, SQL injection or insecure direct object references. In other cases, you can blame misconfigurations, lack of encryption (or weak encryption), non-secure data/control networks, unfettered wireless access, and worse.
Medical devices are incredibly vulnerable to hacking attacks. In some cases it’s because of software defects that allow for exploits, like buffer overflows, SQL injection or insecure direct object references. In other cases, you can blame misconfigurations, lack of encryption (or weak encryption), non-secure data/control networks, unfettered wireless access, and worse.
Why would hackers go after medical devices? Lots of reasons. To name but one: It’s a potential terrorist threat against real human beings. Remember that Dick Cheney famously disabled the wireless capabilities of his implanted heart monitor for fear of an assassination attack.
Certainly healthcare organizations are being targeted for everything from theft of medical records to ransomware. To quote the report “Hacking Healthcare IT in 2016,” from the Institute for Critical Infrastructure Technology (ICIT):
The Healthcare sector manages very sensitive and diverse data, which ranges from personal identifiable information (PII) to financial information. Data is increasingly stored digitally as electronic Protected Health Information (ePHI). Systems belonging to the Healthcare sector and the Federal Government have recently been targeted because they contain vast amounts of PII and financial data. Both sectors collect, store, and protect data concerning United States citizens and government employees. The government systems are considered more difficult to attack because the United States Government has been investing in cybersecurity for a (slightly) longer period. Healthcare systems attract more attackers because they contain a wider variety of information. An electronic health record (EHR) contains a patient’s personal identifiable information, their private health information, and their financial information.
EHR adoption has increased over the past few years under the Health Information Technology and Economics Clinical Health (HITECH) Act. Stan Wisseman [from Hewlett-Packard] comments, “EHRs enable greater access to patient records and facilitate sharing of information among providers, payers and patients themselves. However, with extensive access, more centralized data storage, and confidential information sent over networks, there is an increased risk of privacy breach through data leakage, theft, loss, or cyber-attack. A cautious approach to IT integration is warranted to ensure that patients’ sensitive information is protected.”
Let’s talk devices. Those could be everything from emergency-room monitors to pacemakers to insulin pumps to X-ray machines whose radiation settings might be changed or overridden by malware. The ICIT report says,
Mobile devices introduce new threat vectors to the organization. Employees and patients expand the attack surface by connecting smartphones, tablets, and computers to the network. Healthcare organizations can address the pervasiveness of mobile devices through an Acceptable Use policy and a Bring-Your-Own-Device policy. Acceptable Use policies govern what data can be accessed on what devices. BYOD policies benefit healthcare organizations by decreasing the cost of infrastructure and by increasing employee productivity. Mobile devices can be corrupted, lost, or stolen. The BYOD policy should address how the information security team will mitigate the risk of compromised devices. One solution is to install software to remotely wipe devices upon command or if they do not reconnect to the network after a fixed period. Another solution is to have mobile devices connect from a secured virtual private network to a virtual environment. The virtual machine should have data loss prevention software that restricts whether data can be accessed or transferred out of the environment.
The Internet of Things – and the increased prevalence of medical devices connected hospital or home networks – increase the risk. What can you do about it? The ICIT report says,
The best mitigation strategy to ensure trust in a network connected to the internet of things, and to mitigate future cyber events in general, begins with knowing what devices are connected to the network, why those devices are connected to the network, and how those devices are individually configured. Otherwise, attackers can conduct old and innovative attacks without the organization’s knowledge by compromising that one insecure system.
Given how common these devices are, keeping IT in the loop may seem impossible — but we must rise to the challenge, ICIT says:
If a cyber network is a castle, then every insecure device with a connection to the internet is a secret passage that the adversary can exploit to infiltrate the network. Security systems are reactive. They have to know about something before they can recognize it. Modern systems already have difficulty preventing intrusion by slight variations of known malware. Most commercial security solutions such as firewalls, IDS/ IPS, and behavioral analytic systems function by monitoring where the attacker could attack the network and protecting those weakened points. The tools cannot protect systems that IT and the information security team are not aware exist.
The home environment – or any use outside the hospital setting – is another huge concern, says the report:
Remote monitoring devices could enable attackers to track the activity and health information of individuals over time. This possibility could impose a chilling effect on some patients. While the effect may lessen over time as remote monitoring technologies become normal, it could alter patient behavior enough to cause alarm and panic.
Pain medicine pumps and other devices that distribute controlled substances are likely high value targets to some attackers. If compromise of a system is as simple as downloading free malware to a USB and plugging the USB into the pump, then average drug addicts can exploit homecare and other vulnerable patients by fooling the monitors. One of the simpler mitigation strategies would be to combine remote monitoring technologies with sensors that aggregate activity data to match a profile of expected user activity.
A major responsibility falls onto the device makers – and the programmers who create the embedded software. For the most part, they are simply not up to the challenge of designing secure devices, and may not have the polices, practices and tools in place to get cybersecurity right. Regrettably, the ICIT report doesn’t go into much detail about the embedded software, but does state,
Unlike cell phones and other trendy technologies, embedded devices require years of research and development; sadly, cybersecurity is a new concept to many healthcare manufacturers and it may be years before the next generation of embedded devices incorporates security into its architecture. In other sectors, if a vulnerability is discovered, then developers rush to create and issue a patch. In the healthcare and embedded device environment, this approach is infeasible. Developers must anticipate what the cyber landscape will look like years in advance if they hope to preempt attacks on their devices. This model is unattainable.
In November 2015, Bloomberg Businessweek published a chilling story, “It’s Way too Easy to Hack the Hospital.” The authors, Monte Reel and Jordon Robertson, wrote about one hacker, Billy Rios:
Shortly after flying home from the Mayo gig, Rios ordered his first device—a Hospira Symbiq infusion pump. He wasn’t targeting that particular manufacturer or model to investigate; he simply happened to find one posted on EBay for about $100. It was an odd feeling, putting it in his online shopping cart. Was buying one of these without some sort of license even legal? he wondered. Is it OK to crack this open?
Infusion pumps can be found in almost every hospital room, usually affixed to a metal stand next to the patient’s bed, automatically delivering intravenous drips, injectable drugs, or other fluids into a patient’s bloodstream. Hospira, a company that was bought by Pfizer this year, is a leading manufacturer of the devices, with several different models on the market. On the company’s website, an article explains that “smart pumps” are designed to improve patient safety by automating intravenous drug delivery, which it says accounts for 56 percent of all medication errors.
Rios connected his pump to a computer network, just as a hospital would, and discovered it was possible to remotely take over the machine and “press” the buttons on the device’s touchscreen, as if someone were standing right in front of it. He found that he could set the machine to dump an entire vial of medication into a patient. A doctor or nurse standing in front of the machine might be able to spot such a manipulation and stop the infusion before the entire vial empties, but a hospital staff member keeping an eye on the pump from a centralized monitoring station wouldn’t notice a thing, he says.
The 97-page ICIT report makes some recommendations, which I heartily agree with.
- With each item connected to the internet of things there is a universe of vulnerabilities. Empirical evidence of aggressive penetration testing before and after a medical device is released to the public must be a manufacturer requirement.
- Ongoing training must be paramount in any responsible healthcare organization. Adversarial initiatives typically start with targeting staff via spear phishing and watering hole attacks. The act of an ill- prepared executive clicking on a malicious link can trigger a hurricane of immediate and long term negative impact on the organization and innocent individuals whose records were exfiltrated or manipulated by bad actors.
- A cybersecurity-centric culture must demand safer devices from manufacturers, privacy adherence by the healthcare sector as a whole and legislation that expedites the path to a more secure and technologically scalable future by policy makers.
This whole thing is scary. The healthcare industry needs to set up its game on cybersecurity.
 Cybercriminals want your credentials and your employees’ credentials. When those hackers succeed in stealing that information, it can be bad for individuals – and even worse for corporations and other organizations. This is a scourge that’s bad, and it will remain bad.
Cybercriminals want your credentials and your employees’ credentials. When those hackers succeed in stealing that information, it can be bad for individuals – and even worse for corporations and other organizations. This is a scourge that’s bad, and it will remain bad.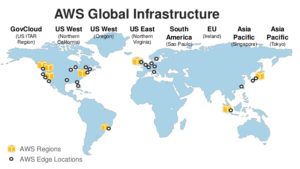 You keep reading the same three names over and over again. Amazon Web Services. Google Cloud Platform. Microsoft Windows Azure. For the past several years, that’s been the top tier, with a wide gap between them and everyone else. Well, there’s a fourth player, the IBM cloud, with their SoftLayer acquisition. But still, it’s AWS in the lead when it comes to Infrastructure-as-a-Service (IaaS) and Platform-as-a-Service (PaaS), with many estimates showing about a 37-40% market share in early 2017. In second place, Azure, at around 28-31%. Third, place, Google at around 16-18%. Fourth place, IBM SoftLayer, at 3-5%.
You keep reading the same three names over and over again. Amazon Web Services. Google Cloud Platform. Microsoft Windows Azure. For the past several years, that’s been the top tier, with a wide gap between them and everyone else. Well, there’s a fourth player, the IBM cloud, with their SoftLayer acquisition. But still, it’s AWS in the lead when it comes to Infrastructure-as-a-Service (IaaS) and Platform-as-a-Service (PaaS), with many estimates showing about a 37-40% market share in early 2017. In second place, Azure, at around 28-31%. Third, place, Google at around 16-18%. Fourth place, IBM SoftLayer, at 3-5%. Cloud-based firewalls come in two delicious flavors: vanilla and strawberry. Both flavors are software that checks incoming and outgoing packets to filter against access policies and block malicious traffic. Yet they are also quite different. Think of them as two essential network security tools: Both are designed to protect you, your network, and your real and virtual assets, but in different contexts.
Cloud-based firewalls come in two delicious flavors: vanilla and strawberry. Both flavors are software that checks incoming and outgoing packets to filter against access policies and block malicious traffic. Yet they are also quite different. Think of them as two essential network security tools: Both are designed to protect you, your network, and your real and virtual assets, but in different contexts. Want to open up your eyes, expand your horizons, and learn from really smart people? Attend a conference or trade show. Get out there. Meet people. Have conversations. Network. Be inspired by keynotes. Take notes in classes that are delivering great material, and walk out of boring sessions and find something better.
Want to open up your eyes, expand your horizons, and learn from really smart people? Attend a conference or trade show. Get out there. Meet people. Have conversations. Network. Be inspired by keynotes. Take notes in classes that are delivering great material, and walk out of boring sessions and find something better. According to a recent study, 46% of the top one million websites are considered risky. Why? Because the homepage or background ad sites are running software with known vulnerabilities, the site was categorized as a known bad for phishing or malware, or the site had a security incident in the past year.
According to a recent study, 46% of the top one million websites are considered risky. Why? Because the homepage or background ad sites are running software with known vulnerabilities, the site was categorized as a known bad for phishing or malware, or the site had a security incident in the past year. Once upon a time, goes the story, there was honor between thieves and victims. They held a member of your family for ransom; you paid the ransom; they left you alone. The local mob boss demanded protection money; if you didn’t pay, your business burned down, but if you did pay and didn’t rat him out to the police, his and his gang honestly tried to protect you. And hackers may have been operating outside legal boundaries, but for the most part, they were explorers and do-gooders intending to shine a bright light on the darkness of the Internet – not vandals, miscreants, hooligans and ne’er-do-wells.
Once upon a time, goes the story, there was honor between thieves and victims. They held a member of your family for ransom; you paid the ransom; they left you alone. The local mob boss demanded protection money; if you didn’t pay, your business burned down, but if you did pay and didn’t rat him out to the police, his and his gang honestly tried to protect you. And hackers may have been operating outside legal boundaries, but for the most part, they were explorers and do-gooders intending to shine a bright light on the darkness of the Internet – not vandals, miscreants, hooligans and ne’er-do-wells. When an employee account is compromised by malware, the malware establishes a foothold on the user’s computer – and immediately tries to gain access to additional resources. It turns out that with the right data gathering tools, and with the right Big Data analytics and machine-learning methodologies, the anomalous network traffic caused by this activity can be detected – and thwarted.
When an employee account is compromised by malware, the malware establishes a foothold on the user’s computer – and immediately tries to gain access to additional resources. It turns out that with the right data gathering tools, and with the right Big Data analytics and machine-learning methodologies, the anomalous network traffic caused by this activity can be detected – and thwarted. Are you a coder? Architect? Database guru? Network engineer? Mobile developer? User-experience expert? If you have hands-on tech skills, get those hands dirty at a Hackathon.
Are you a coder? Architect? Database guru? Network engineer? Mobile developer? User-experience expert? If you have hands-on tech skills, get those hands dirty at a Hackathon. Thank you, NetGear, for taking care of your valued customers. On July 1, the company announced that it would be shutting down the proprietary back-end cloud services required for its VueZone cameras to work – turning them into expensive camera-shaped paperweights. See “
Thank you, NetGear, for taking care of your valued customers. On July 1, the company announced that it would be shutting down the proprietary back-end cloud services required for its VueZone cameras to work – turning them into expensive camera-shaped paperweights. See “ In the “you learn something every day” department: Discovered today that there’s a plaque at Stanford honoring the birth of the Internet. The plaque was dedicated on July 28, 2005, and is in the
In the “you learn something every day” department: Discovered today that there’s a plaque at Stanford honoring the birth of the Internet. The plaque was dedicated on July 28, 2005, and is in the  There are standards for everything, it seems. And those of us who work on Internet things are often amused (or bemused) by what comes out of the
There are standards for everything, it seems. And those of us who work on Internet things are often amused (or bemused) by what comes out of the  The MEF recently conducted its second LSO Hackathon at a Rome event called Euro16. You can read my story about it here in DiarioTi:
The MEF recently conducted its second LSO Hackathon at a Rome event called Euro16. You can read my story about it here in DiarioTi:  WiFi is the present and future of local area networking. Forget about families getting rid of the home phone. The real cable-cutters are dropping the Cat-5 Ethernet in favor of
WiFi is the present and future of local area networking. Forget about families getting rid of the home phone. The real cable-cutters are dropping the Cat-5 Ethernet in favor of  Fire up the
Fire up the  Security standards for cellular communications are pretty much invisible. The security standards, created by groups like the 3GPP, play out behind the scenes, embedded into broader cellular protocols like 3G, 4G, LTE and the oft-discussed forthcoming 5G. Due to the nature of the security and other cellular specs, they evolve very slowly and deliberately; it’s a snail-like pace compared to, say, WiFi or Bluetooth.
Security standards for cellular communications are pretty much invisible. The security standards, created by groups like the 3GPP, play out behind the scenes, embedded into broader cellular protocols like 3G, 4G, LTE and the oft-discussed forthcoming 5G. Due to the nature of the security and other cellular specs, they evolve very slowly and deliberately; it’s a snail-like pace compared to, say, WiFi or Bluetooth. Forget vendor lock-in: Carrier operation support systems (OSS) and business support systems (BSS) are going open source. And so are many of the other parts of the software stack that drive the end-to-end services within and between carrier networks.
Forget vendor lock-in: Carrier operation support systems (OSS) and business support systems (BSS) are going open source. And so are many of the other parts of the software stack that drive the end-to-end services within and between carrier networks. Get used to new names.
Get used to new names.  The Panama Papers should be a wake-up call to every CEO, COO, CTO and CIO in every company.
The Panama Papers should be a wake-up call to every CEO, COO, CTO and CIO in every company. Barcelona, Mobile World Congress 2016—IoT success isn’t about device features, like long-life batteries, factory-floor sensors and snazzy designer wristbands. The real power, the real value, of the Internet of Things is in the data being transmitted from devices to remote servers, and from those remote servers back to the devices.
Barcelona, Mobile World Congress 2016—IoT success isn’t about device features, like long-life batteries, factory-floor sensors and snazzy designer wristbands. The real power, the real value, of the Internet of Things is in the data being transmitted from devices to remote servers, and from those remote servers back to the devices. A hackathon – like the debut
A hackathon – like the debut  Software-defined networks and Network Functions Virtualization will redefine enterprise computing and change the dynamics of the cloud. Data thefts and professional hacks will grow, and development teams will shift their focus from adding new features to hardening against attacks. Those are two of my predictions for 2015.
Software-defined networks and Network Functions Virtualization will redefine enterprise computing and change the dynamics of the cloud. Data thefts and professional hacks will grow, and development teams will shift their focus from adding new features to hardening against attacks. Those are two of my predictions for 2015.
 Washington, D.C. — “It’s not time to regulate and control and tax the Internet.” Those are words of wisdom about Net Neutrality from Dr. Robert Metcalfe, inventor of Ethernet, held here at the
Washington, D.C. — “It’s not time to regulate and control and tax the Internet.” Those are words of wisdom about Net Neutrality from Dr. Robert Metcalfe, inventor of Ethernet, held here at the  HTML browser virtualization, not APIs, may be the best way to mobilize existing enterprise applications like SAP ERP, Oracle E-Business Suite or Microsoft Dynamics.
HTML browser virtualization, not APIs, may be the best way to mobilize existing enterprise applications like SAP ERP, Oracle E-Business Suite or Microsoft Dynamics. l Sedaka insists that
l Sedaka insists that  “My name is Patricia from the Bank of America fraud prevention department. This important message is for Mr. Alan Zeichick. We are calling to verify some potentially suspicious activity on your account. It is very important that we speak with you.”
“My name is Patricia from the Bank of America fraud prevention department. This important message is for Mr. Alan Zeichick. We are calling to verify some potentially suspicious activity on your account. It is very important that we speak with you.” Cloud-based development tools are great. Until they don’t work.
Cloud-based development tools are great. Until they don’t work. We drove slightly more than 2,500 miles (4,000 kilometers), my wife and I, during a weeklong holiday. We explored different states in the western United States: Arizona (where we live), Colorado, New Mexico and Wyoming. The Rocky Mountains are incredible. Most of our vacation was at altitudes above 6,000 feet (1,800 meters). Many of the mountain peaks were above 14,000 feet (4,200 meters), and one road went above 11,000 feet (3,300 meters). Exciting!
We drove slightly more than 2,500 miles (4,000 kilometers), my wife and I, during a weeklong holiday. We explored different states in the western United States: Arizona (where we live), Colorado, New Mexico and Wyoming. The Rocky Mountains are incredible. Most of our vacation was at altitudes above 6,000 feet (1,800 meters). Many of the mountain peaks were above 14,000 feet (4,200 meters), and one road went above 11,000 feet (3,300 meters). Exciting!