 The best way to have a butt-kicking cloud-native application is to write one from scratch. Leverage the languages, APIs, and architecture of the chosen cloud platform before exploiting its databases, analytics engines, and storage. As I wrote for Ars Technica, this will allow you to take advantage of the wealth of resources offered by companies like Microsoft, with their Azure PaaS (Platform-as-a-Service) offering or by Google Cloud Platform’s Google App Engine PaaS service.
The best way to have a butt-kicking cloud-native application is to write one from scratch. Leverage the languages, APIs, and architecture of the chosen cloud platform before exploiting its databases, analytics engines, and storage. As I wrote for Ars Technica, this will allow you to take advantage of the wealth of resources offered by companies like Microsoft, with their Azure PaaS (Platform-as-a-Service) offering or by Google Cloud Platform’s Google App Engine PaaS service.
Sometimes, however, that’s not the job. Sometimes, you have to take a native application running on a server in your local data center or colocation facility and make it run in the cloud. That means virtual machines.
Before we get into the details, let’s define “native application.” For the purposes of this exercise, it’s an application written in a high-level programming language, like C/C++, C#, or Java. It’s an application running directly on a machine talking to an operating system, like Linux or Windows, that you want to run on a cloud platform like Windows Azure, Amazon Web Services (AWS), or Google Cloud Platform (GCP).
What we are not talking about is an application that has already been virtualized, such as already running within VMware’s ESXi or Microsoft’s Hyper-V virtual machine. Sure, moving an ESXi or Hyper-V application running on-premises into the cloud is an important migration that may improve performance and add elasticity while switching capital expenses to operational expenses. Important, yes, but not a challenge. All the virtual machine giants and cloud hosts have copious documentation to help you make the switch… which amounts to basically copying the virtual machine file onto a cloud server and turning it on.
Many possible scenarios exist for moving a native datacenter application into the cloud. They boil down to two main types of migrations, and there’s no clear reason to choose one over the other:
The first is to create a virtual server within your chosen cloud provider, perhaps running Windows Server or running a flavor of Linux. Once that virtual server has been created, you migrate the application from your on-prem server to the new virtual server—exactly as you would if you were moving from one of your servers to a new server. The benefits: the application migration is straightforward, and you have 100-percent control of the server, the application, and security. The downside: the application doesn’t take advantage of cloud APIs or other special servers. It’s simply a migration that gets a server out of your data center. When you do this, you are leveraging a type of cloud called Infrastructure-as-a-Service (IaaS). You are essentially treating the cloud like a colocation facility.
The second is to see if your application code can be ported to run within the native execution engine provided by the cloud service. This is called Platform-as-a-Service (PaaS). The benefits are that you can leverage a wealth of APIs and other services offered by the cloud provider. The downsides are that you have to ensure that your code can work on the service (which may require recoding or even redesign) in order to use those APIs or even to run at all. You also don’t have full control over the execution environment, which means that security is managed by the cloud provider, not by you.
And of course, there’s the third option mentioned at the beginning: Writing an entirely new application native for the cloud provider’s PaaS. That’s still the best option, if you can do it. But our task today is to focus on migrating an existing application.
Let’s look into this more closely, via my recent article for Ars Technica, “Great app migration takes enterprise “on-prem” applications to the Cloud.”
 When an employee account is compromised by malware, the malware establishes a foothold on the user’s computer – and immediately tries to gain access to additional resources. It turns out that with the right data gathering tools, and with the right Big Data analytics and machine-learning methodologies, the anomalous network traffic caused by this activity can be detected – and thwarted.
When an employee account is compromised by malware, the malware establishes a foothold on the user’s computer – and immediately tries to gain access to additional resources. It turns out that with the right data gathering tools, and with the right Big Data analytics and machine-learning methodologies, the anomalous network traffic caused by this activity can be detected – and thwarted. Medical devices are incredibly vulnerable to hacking attacks. In some cases it’s because of software defects that allow for exploits, like buffer overflows, SQL injection or insecure direct object references. In other cases, you can blame misconfigurations, lack of encryption (or weak encryption), non-secure data/control networks, unfettered wireless access, and worse.
Medical devices are incredibly vulnerable to hacking attacks. In some cases it’s because of software defects that allow for exploits, like buffer overflows, SQL injection or insecure direct object references. In other cases, you can blame misconfigurations, lack of encryption (or weak encryption), non-secure data/control networks, unfettered wireless access, and worse. Thank you, NetGear, for taking care of your valued customers. On July 1, the company announced that it would be shutting down the proprietary back-end cloud services required for its VueZone cameras to work – turning them into expensive camera-shaped paperweights. See “
Thank you, NetGear, for taking care of your valued customers. On July 1, the company announced that it would be shutting down the proprietary back-end cloud services required for its VueZone cameras to work – turning them into expensive camera-shaped paperweights. See “ There are standards for everything, it seems. And those of us who work on Internet things are often amused (or bemused) by what comes out of the
There are standards for everything, it seems. And those of us who work on Internet things are often amused (or bemused) by what comes out of the  Thank you,
Thank you,  Excellent story about SharePoint in ComputerWorld this week. It gives encouragement to those who prefer to run SharePoint in their own data centers (on-premises), rather than in the cloud. In “
Excellent story about SharePoint in ComputerWorld this week. It gives encouragement to those who prefer to run SharePoint in their own data centers (on-premises), rather than in the cloud. In “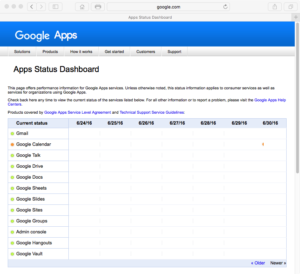 Cloud services crash. Of course, non-cloud-services crash too — a server in your data center can go down, too. At least there you can do something, or if it’s a critical system you can plan with redundancies and failover.
Cloud services crash. Of course, non-cloud-services crash too — a server in your data center can go down, too. At least there you can do something, or if it’s a critical system you can plan with redundancies and failover. I can hear the protesters. “What do we want? Faster automated emails! When do we want them? In under 20 nanoseconds!”
I can hear the protesters. “What do we want? Faster automated emails! When do we want them? In under 20 nanoseconds!” WiFi is the present and future of local area networking. Forget about families getting rid of the home phone. The real cable-cutters are dropping the Cat-5 Ethernet in favor of
WiFi is the present and future of local area networking. Forget about families getting rid of the home phone. The real cable-cutters are dropping the Cat-5 Ethernet in favor of  Fire up the
Fire up the  Forget vendor lock-in: Carrier operation support systems (OSS) and business support systems (BSS) are going open source. And so are many of the other parts of the software stack that drive the end-to-end services within and between carrier networks.
Forget vendor lock-in: Carrier operation support systems (OSS) and business support systems (BSS) are going open source. And so are many of the other parts of the software stack that drive the end-to-end services within and between carrier networks.
 Get used to new names.
Get used to new names.  The Panama Papers should be a wake-up call to every CEO, COO, CTO and CIO in every company.
The Panama Papers should be a wake-up call to every CEO, COO, CTO and CIO in every company. Barcelona, Mobile World Congress 2016—IoT success isn’t about device features, like long-life batteries, factory-floor sensors and snazzy designer wristbands. The real power, the real value, of the Internet of Things is in the data being transmitted from devices to remote servers, and from those remote servers back to the devices.
Barcelona, Mobile World Congress 2016—IoT success isn’t about device features, like long-life batteries, factory-floor sensors and snazzy designer wristbands. The real power, the real value, of the Internet of Things is in the data being transmitted from devices to remote servers, and from those remote servers back to the devices. Software-defined networks and Network Functions Virtualization will redefine enterprise computing and change the dynamics of the cloud. Data thefts and professional hacks will grow, and development teams will shift their focus from adding new features to hardening against attacks. Those are two of my predictions for 2015.
Software-defined networks and Network Functions Virtualization will redefine enterprise computing and change the dynamics of the cloud. Data thefts and professional hacks will grow, and development teams will shift their focus from adding new features to hardening against attacks. Those are two of my predictions for 2015.
 Washington, D.C. — “It’s not time to regulate and control and tax the Internet.” Those are words of wisdom about Net Neutrality from Dr. Robert Metcalfe, inventor of Ethernet, held here at the
Washington, D.C. — “It’s not time to regulate and control and tax the Internet.” Those are words of wisdom about Net Neutrality from Dr. Robert Metcalfe, inventor of Ethernet, held here at the  Malicious agents can crash a website by implementing a DDoS—a Distributed Denial of Service Attack—against a server. So can sloppy programmers.
Malicious agents can crash a website by implementing a DDoS—a Distributed Denial of Service Attack—against a server. So can sloppy programmers. HTML browser virtualization, not APIs, may be the best way to mobilize existing enterprise applications like SAP ERP, Oracle E-Business Suite or Microsoft Dynamics.
HTML browser virtualization, not APIs, may be the best way to mobilize existing enterprise applications like SAP ERP, Oracle E-Business Suite or Microsoft Dynamics. l Sedaka insists that
l Sedaka insists that  You’ve gotta read “
You’ve gotta read “ Cloud-based development tools are great. Until they don’t work.
Cloud-based development tools are great. Until they don’t work. There are lots of reasons to use
There are lots of reasons to use  South San Francisco, California — Writing software would be oh, so much simpler if we didn’t have all those darned choices. HTML5 or native apps? Windows Server in the data center or Windows Azure in the cloud? Which Linux distro? Java or C#? Continuous Integration? Continuous Delivery? Git or Subversion or both? NoSQL? Which APIs? Node.js? Follow-the-sun?
South San Francisco, California — Writing software would be oh, so much simpler if we didn’t have all those darned choices. HTML5 or native apps? Windows Server in the data center or Windows Azure in the cloud? Which Linux distro? Java or C#? Continuous Integration? Continuous Delivery? Git or Subversion or both? NoSQL? Which APIs? Node.js? Follow-the-sun?